品名予測の技術紹介
OPENLOGI Advent Calendar 2021 の13日目の記事です。
今年から、OPENLOGI というベンチャーで、会社で1人目の機械学習エンジニアとして働いています。 弊社は物流プラットフォームサービスを開発しており、今年から機械学習やデータ分析、数理最適化を通して物流を効率化しよう!という取り組みを始めました。 その一環で品名予測を Keras で実装したのですが、諸事情で使われないことになってしまいました。 悲しいので、供養のために技術面の話をここで紹介したいと思います。
品名とは?
大抵の方は、荷物を送るときにクロネコヤマトや佐川急便、郵便局を利用したことがあると思います。 そのとき、荷物の送り状(伝票)にダンボール箱の中身に何が入っているか書いた経験があるのではないでしょうか? 例えば、どこかのブランドの服を送る時は「衣料品」、とらやの羊羹セットをおくるときは「羊羹」などと書くと思います。 書き方については、佐川急便のヘルプページがわかりやすいと思います。
品名は、配達員が荷物を届けるときには「割れやすいか」「上に物を乗せて大丈夫か」などを判断するために必要な情報です。 しかし、配送会社側でも明確な定義は作っておらず、「こんな感じで書いてね」という具体例程度の情報しかありません。 このため、商品によってはいい感じの品名を思いつくのが難しかったりします。
品名予測とは?
弊社では、お客様のお荷物をお預かりして、配送することが日常的に行われています。 商品を送る際に、お客様に入力してもらった品名をもとに「配達員にとってわかりやすい品名」を予測するタスクを「品名予測」と呼んでいます。 例えば、「Perfume Single Vol.1」みたいな品名が入力されると、「CD/DVD」のように訂正した品名を推定します。 このような商品名に近い文字列が品名として入力されることが多く、品名訂正を自動化したいという要望が社内にありました。
予測システムの入力は
- お客様に入力してもらった品名(ヒント品名)
- 商品名
- 商品の大きさと重量
であり、出力は
- 配達員にとってわかりやすい品名(出力品名)
です。
出力品名は人間が作った教師データが数万件あるので、これを使って教師あり学習をします。
技術の概要
今回は以下のような技術セットで実現しました。
Seq2seq を選んだ明確な理由はないです。 今時は Transformer を使うのが主流なので、次は Transformer ベースの深層NNの事前学習モデルを改造していく方針でやりたいですね。
ライブラリに関しても、PyTorch でモデルを組んで JAX で学習して、 学習済みモデルを TFLite にエクスポートして Tensorflow で予測を回すみたいなピタゴラスイッチをどこかで見かけたので、 試してみたいですね。
前処理
ヒント品名と商品名は自然言語なので、一般的な自然言語処理でよく使われる前処理をかけています。
- neologd 正規化
- 形態素解析
- ストップワード除去
- その他の正規化処理
商品サイズと重量に関してはビニングすることで、カテゴリカル素性に変換しています。
形態素解析
自然言語で書かれた文字列を単語のリストに分解する処理を形態素解析といいます。 英語などでは必要ありませんが、日本語のように分かち書きされていない言語では必要な処理です。 最近は形態素解析せずに文字単位で直接処理できるニューラルネットもありますが、今回は単語単位で処理することにしました。
形態素解析は昔から研究されているトピックで、既に簡単に使えるツールがあります。 ツールとしては MeCab が一番有名ですね。 条件付き確率場を使っていて、非常に高速で使いやすいインタフェースです。 色々な言語でバインディングライブラリがあるので、Python や C 以外で形態素解析する場合も有力な選択肢になります。 Mac なら brew でインストールできます。
brew install mecab mecab-ipadic mecab
最近寒いですがお元気でしょうか? と入力すると、こんな感じで解析結果を出してくれます。
最近 名詞,副詞可能,*,*,*,*,最近,サイキン,サイキン 寒い 形容詞,自立,*,*,形容詞・アウオ段,基本形,寒い,サムイ,サムイ です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス が 助詞,接続助詞,*,*,*,*,が,ガ,ガ お 接頭詞,名詞接続,*,*,*,*,お,オ,オ 元気 名詞,形容動詞語幹,*,*,*,*,元気,ゲンキ,ゲンキ でしょ 助動詞,*,*,*,特殊・デス,未然形,です,デショ,デショ う 助動詞,*,*,*,不変化型,基本形,う,ウ,ウ か 助詞,副助詞/並立助詞/終助詞,*,*,*,*,か,カ,カ ? 記号,一般,*,*,*,*,?,?,? EOS
他にもいろいろな形態素解析の実装がありますが、MeCab で事足りることが多いので、個人的には MeCab を使うことが多いです。
形態素解析をやる場合は辞書でかなり精度が変わります。
辞書に関してはデフォルトの ipadic よりも mecab-ipadic-neologd が優秀です。
この辞書を使ったときに この素晴らしき世界に祝福を が固有名詞として認識された時はさすがに驚きました。
たぶん、私よりも語彙力があります。うらやま
ストップワード除去
ストップワード除去は出現頻度が高すぎる単語をあらかじめ除去しておくことです。 日本語でよく見かけるのは「です」「ます」「は」などの助詞ですね。 こういった単語は、ほとんど予測の役に立たないので削除します。
その他の正規化処理
【】《》×「」『』〈〉〔〕=〜※・! などの無意味な記号を除去したり、細かく雑多な前処理を追加でかけています。
よく使われる s/[0-9]+/0/g という変換もかけています。
例えば、USB扇風機 2021年最新モデル を USB扇風機 0年最新モデル に書き換えるような前処理です。
数字の細かい値は予測に関係ないので、情報を捨てて、単語数を減らしています。
モデル
ニューラルネットの全体の構造は以下のようになっています。 基本的には Encoder+Decoder で構成される Seq2seq モデルを拡張したような構造になっています。
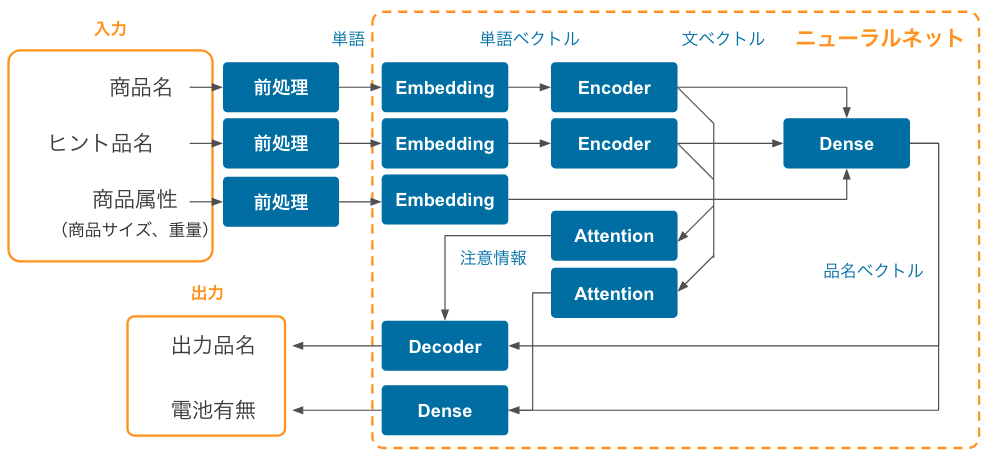
※ 航空便などでは電池の有無で配送不可になることがあるので、出力品名とはわけて予測しています。
Embedding
人が読み書きする言語には必ず、類義語や表記揺れがあります。 例えば、「MacBook」と「レッツノート」は似たような意味の単語ですが、文字列としては全然違います。 文字列だけで比較してしまうと、両者から「ノートパソコン」という同じ品名を導くことが難しいので、 類義語や表記揺れを吸収した「単語の意味っぽい」情報を取り出す必要があります。 この処理を担当するのが Embedding レイヤーです。
専門的には、Embedding レイヤーは単語の Bag-of-words 表現を分散表現という密ベクトルに次元圧縮する処理を行います。 この密ベクトルのコサイン類似度は直感的な単語の類似度に近くなることが知られています。 気になる方は Word2vec で調べてみてください。深い沼が貴方を待っています。
Seq2seq Encoder
Seq2seq の Encoder は入力単語列(正確には入力単語の分散表現の列)を受け取って、context というベクトルにまとめる処理を担当します。 例えば、以下に「岩下の新生姜ファミリーパック」という商品名を入力した場合のネットワーク構造を図示しています。
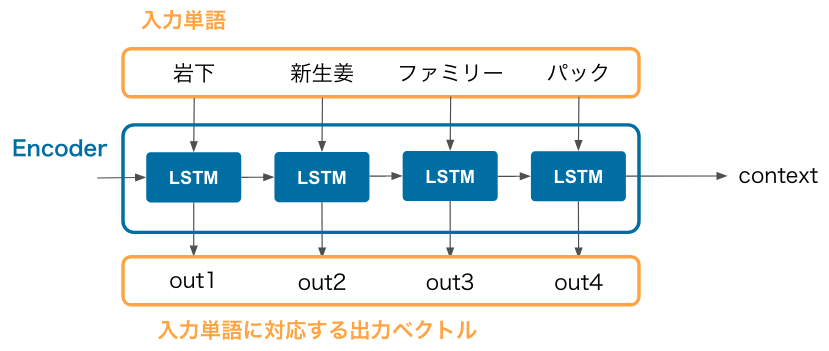
Recurrent Neural Network の一種である LSTM を連結した構造になっており、 入力単語の個数に関係なく、固定長の context ベクトルが得られる点が Seq2seq の特徴です。 context は商品名全体の特徴を持ったベクトルなので、このベクトルに対して色々と処理ができます。
入力単語に対応する出力ベクトルは Attention レイヤーに渡されます。
Seq2seq Decoder
Seq2seq の Decoder は Encoder の成果物である context を受け取って、出力品名の単語を1つずつ予測します。 例えば、先程の「岩下の新生姜ファミリーパック」に対して「生姜酢漬け」という品名を予測する場合は以下のようになります。
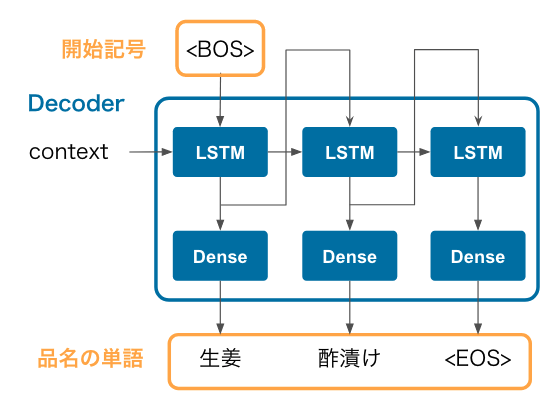
- まず、LSTM の入力に
<BOS>(文字列の開始を意味する特殊記号)を入力すると、生姜という単語が出力されます。 - 前のステップで得られた
生姜の出力ベクトルを次の LSTM の入力に入れると酢漬けという単語が出力されます。 - さらにこの
酢漬けの出力ベクトルを次の LSTM の入力に入れると<EOS>という文字列の終端を意味する特殊記号が出力されます。この記号が得られた時点で予測を止めます。
このように、1つ前の単語を LSTM に入力して、次の単語を予測する、という処理を繰り返して品名全体を予測します。
精度
Decoder で出力品名を求めるときに、単語列の同時確率を計算しておきます。 基本的には同時確率が高いほど、出力品名の信頼性が高いと考えられます。 適当にしきい値を決めて、この同時確率がしきい値を超えた品名だけ予測品名を採用し、 しきい値未満の品名は人間が確認するような Human-in-the-loop の運用を想定してみます。 興味があるのは、
- 自動化率:予測器に担当させられる(=しきい値を超える)品名の割合
- 精度:予測器に担当させた品名のうち、正解する品名の割合
の2つです。
今回実装したモデルでは、自動化率 36 %、精度 99.5 % で当てることができました。 半分以上の商品では、まだ十分な精度を出せませんでしたが、社内では「実戦投入しても良さそう」と思ってもらえるだけの精度を出すことができました。
プロジェクトが中止になったのは精度とは関係ない事情なので、初期実装としてはギリギリ使える数字になったと思います。
反省点
Seq2seq じゃなくて Transformer ベースの既存の DNN の事前学習モデルをベースに組み立てれば良かったな、と思っています。 多分その方が、少ない労力でもっと高精度を叩き出せたのではないかと考えています。
RECore でモーターを動かしてみた
RECore はモーターを直接繋げるバッテリー付きマイコンボードで、Raspberry Pi や Arduino よりも簡単にロボットが作れます。 先日、Lチカして遊んでみました が、今度はモーターを動かしてみました。 L チカは Arduino にもできますが、モーターを直接繋げるマイコンボードは RECore だけです。 結論から言えば、特にトラブルもなくすぐに動いて、すごく簡単でした!
組み立て
家に手頃なモーターがなかったので、タミヤのパーツを買ってきました。全部でだいたい 1200 円くらい。
- タミヤ 楽しい工作シリーズ ボールキャスター - ヨドバシ.com
- タミヤ 楽しい工作シリーズ オフロードタイヤセット - ヨドバシ.com
- タミヤ 楽しい工作シリーズ ツインモーターギヤーボックス - ヨドバシ.com
写真のタイヤセットは 4 個セットのものですが、2 個しか使わないので、2 個セットを買うのがお得です。

説明書にしたがって、ギヤボックスとボールキャスターを組み立てます。 RECore の底面にはタミヤギヤボックス用の穴が空いているので、適当な位置にねじ止めし、ボールキャスターは両面テープでくっつけます。

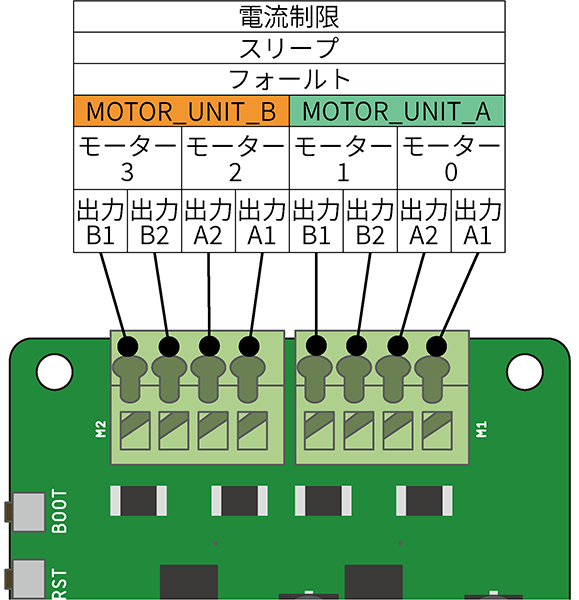
モーターのコードはこんな感じで Motor Unit A につなぎます。 どっちが正回転でどっちが逆回転なのかはわかりませんが、そこは動作させてみて考えることにしましょう。

プログラム
公式チュートリアルのモーターの内容にしたがって、プログラムを作ります。
ほとんどチュートリアルのままですが、速度を変えて方向転換するようにしてみます。
#include "RECoreLibrary.h" RECoreLibrary recore; void setup() { recore.setMotorType(MOTOR_UNIT_A, SINGLE_DC); // Unit A をシングルモードにする recore.setMotorCurrent(500); // 500mA } void loop() { recore.setMotorSpeed(0, 1.0); recore.setMotorSpeed(1, 1.0); delay(2000); recore.setMotorSpeed(0, 0.0); recore.setMotorSpeed(1, 1.0); delay(500); }
タミヤのモーターに何アンペア流せるのか全くわかりませんが、適当に 500 mA で設定しました。 実際どれくらいがいいんでしょうね?詳しい人教えて。
書き込み&実行
書き込む前に Arduino IDE でボードが RECore になっていることを確認します。
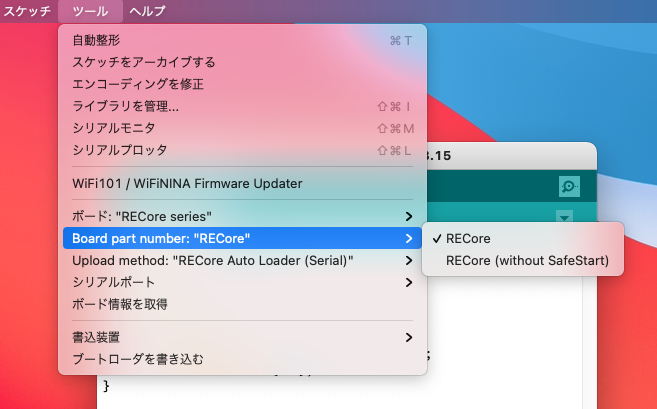
この状態だと SafeStart と言って、書き込んだ後に本体のタクトスイッチを押して、ユーザプログラムの実行を始める方式です。
RECore (without SafeStart) を選択すると、書き込んだ直後に実行が始まりますが、これだと USB ケーブルを引きずったまま走り出すので危険です。
書き込んだ後、RECore 本体の LED がフワフワ点滅するので、その状態でタクトスイッチを押すと、軽快に走り出します。
RECore 動いた! pic.twitter.com/OWZDBLnsZl
— あっきー(慢性五月病) (@ackey_65535) 2021年11月21日
感想
本当に数行のプログラムで簡単にモーターを動かすことができました! びっくりするほど簡単で、むしろ拍子抜けしてしまいますね。 これが Arduino ならモータードライバーを経由して繋ぐ必要がありますし、自走させるためには電池も積まないといけません。 それ考えると、かなり簡略化されていると思います。
RECore はロボット用のマイコンボードなだけあって、ハード・ソフト共にモーターを使うことが非常に楽です。 これで何か面白いもの作りたいですね!まだ、アイディアはないですが。。。
RECoreでLチカしてみた
縁あっておもしろいデバイスを手に入れたので、ちょっと遊んでみました。 Omniment が作っている RECore という商品で、今年の夏くらいに発売したようです。 ざっくりいえば、「モーターを直接繋げるバッテリー付きマイコンボード」。
マイコンボードといえば、Arduino UNO とか Raspberry Pi が有名どころですが、ロボットに組み込もうと思うと色々とお膳立てが必要です。 モーターを動かすためにモータードライバーを付けたり、バッテリーの保護回路を考えたり・・・
RECore はその辺の悩みを解決してくれるデバイスです。 モータードライバーを内蔵していて、モーターを直接繋いでも大丈夫な専用のIO端子を持っていることに加え、 バッテリーも内蔵しているので、単独でマイコンとモーターを駆動できます。 キャッチコピーの「ロボットの種」という言葉通り、小型のロボット向けのマイコンボードと言って良さそうです。 13,800円と他のマイコンボードよりお高めですが、モータードライバーとモバイルバッテリーが付属していると考えると、極端に高いわけではないと思います。 いくつかのECで取り扱いがありますが、本家とスイッチサイエンスのリンクを貼っておきます。
開封の儀

Apple とか Anker みを感じるシンプルな箱にまとまっています。 Raspberry Pi 3 の箱より少し大きいですね。

中には RECore 本体、USB ケーブル、説明書が入っています。 説明書はありがちなポエムではなく、ピン配置や操作方法など実用的な内容が書いてあります。 Arduino や Raspberry Pi のピン配置は覚えられずに毎回ググっているので、親切だと感じました。 本体はバッテリーを内蔵しているので、Raspberry Pi 3 よりも高さがありますが、基板自体はむしろわずかに小さいですね。 左が RECore、右が Raspberry Pi 3 です。RECore が大きく見えるのは、RECore 自体の高さによる遠近法です。

ARM Cortex を搭載していて、バッテリーは定格 7.2V (10.8Wh) 。 DCモーターなら4個、ステッピングモーターなら2個接続可能で、各1Aまで駆動できます。 バッテリー込みのマイコンボードとして非常にコンパクトにまとまっているので、ちょっとしたロボットを作るのには良さそうです。
開発環境の構築
ARM を積んでいますが、Arduino IDE が使えるので、簡単に開発を始められます。 まず、ファイル>環境設定を開き、「追加のボードマネージャのURL」の項目に以下のURLを貼り付けます。
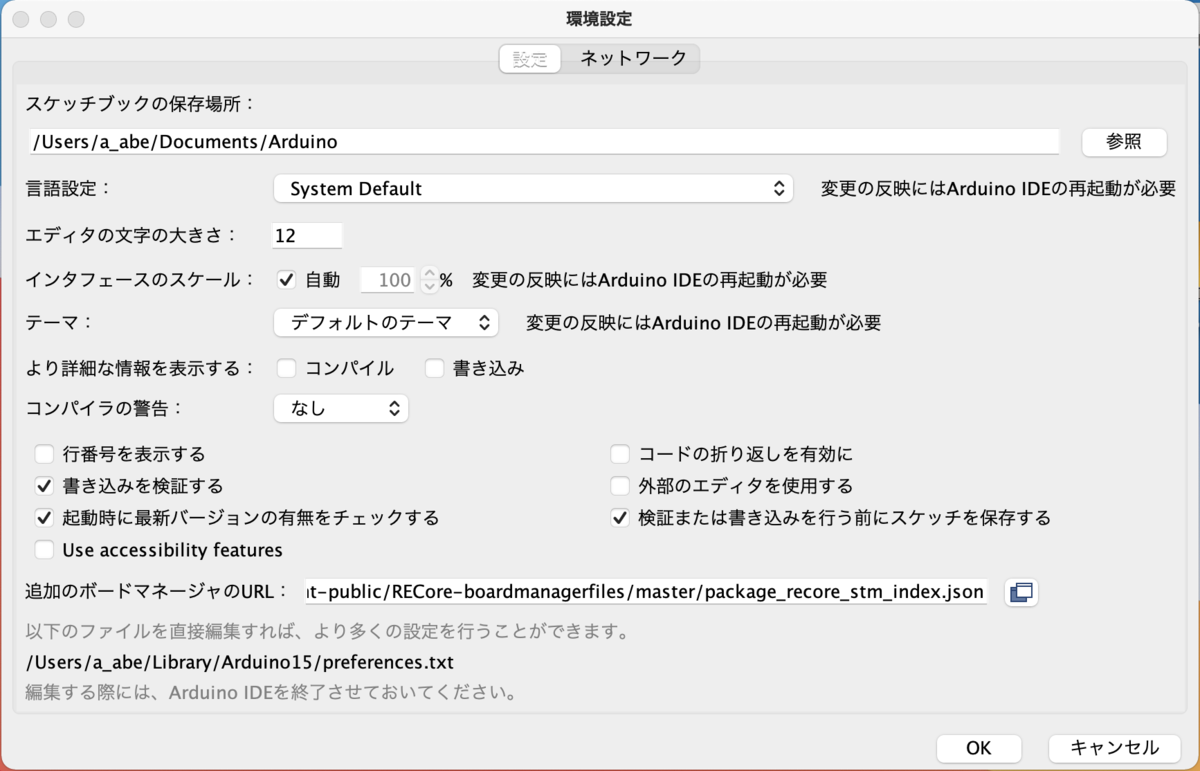
続いて、ツール>ボード>ボードマネージャで RECore を検索してインストールします。
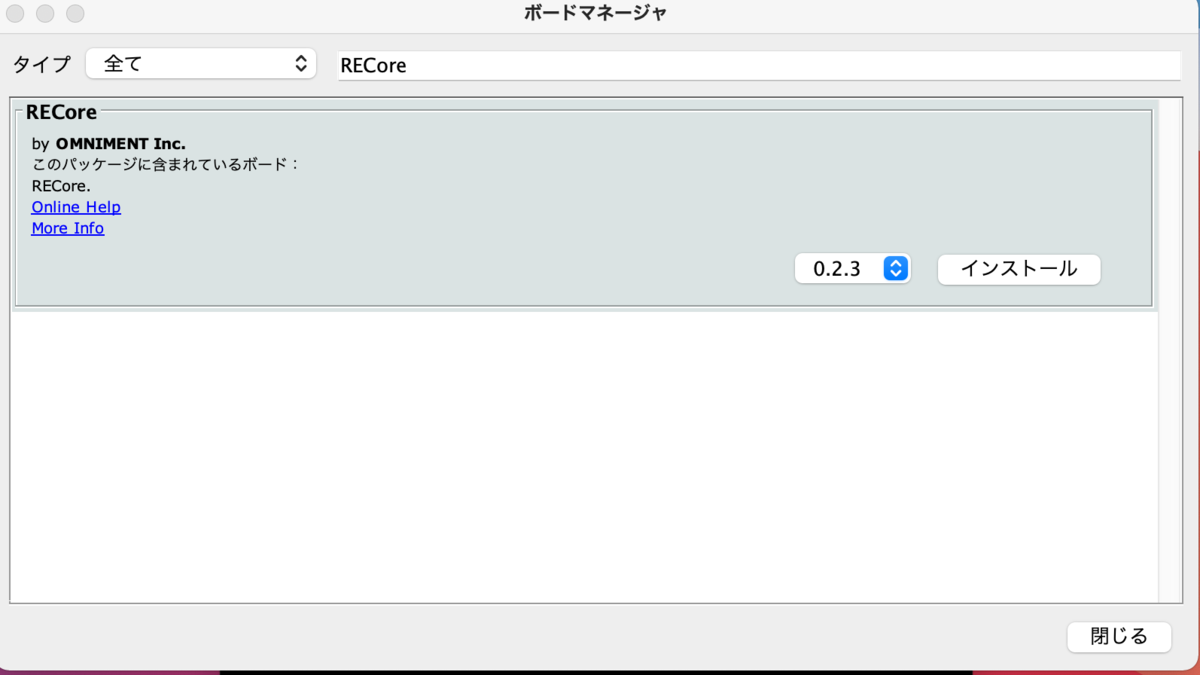
インストールが終わると、ボードに RECore Series が追加されます。
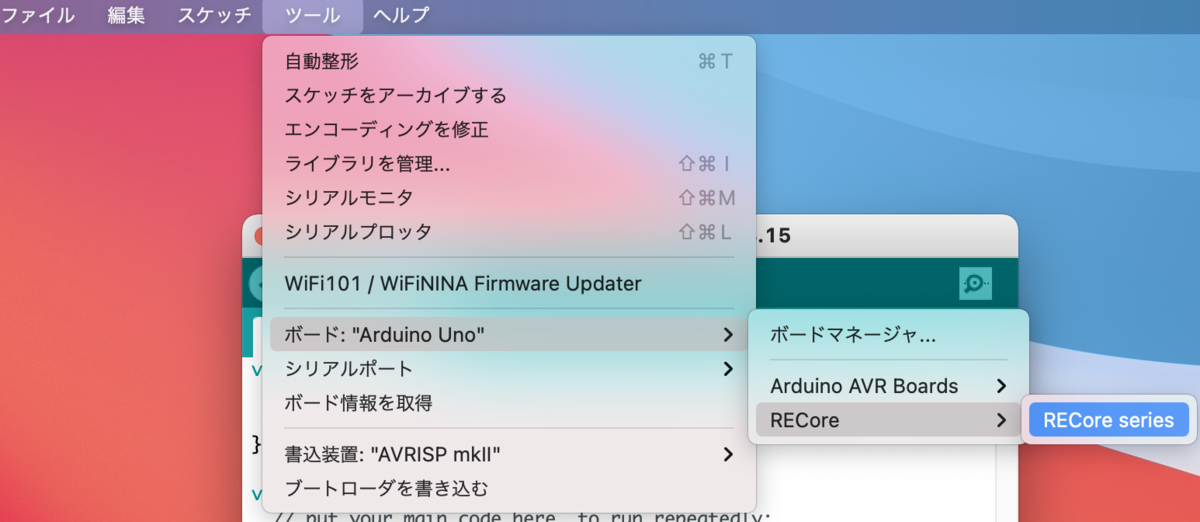
Lチカ
公式 L チカチュートリアル に従って、簡単なコードを書き込んでみます。
void setup() { } void loop() { if(digitalRead(14) == false){ digitalWrite(13,true); }else{ digitalWrite(13,false); } }
注意点として、書き込む前にちゃんと本体の電源を入れておく必要があります。 Arduino や Raspberry Pi と違って、USB コネクタを繋いだだけでは電源が入りません。 考えてみれば当たり前ですが、私は書き込みエラーになって初めて気がつきました(笑)。
タクトスイッチをぽちぽちすると緑色の LED がついたり消えたりします。成功!

(動画も撮ったけど、直接アップロードできないので、掲載を断念しました。)
感想
簡単と聞いていたけれど、本当に Arduino 並みに簡単に使えて少し驚きました。 Arduino IDE を使える上に、ライブラリも似たようなインタフェースになっているので、使い勝手は完全に Arduino ですね。 Arduino とは違って、ライブラリにモータードライバー関連の機能が追加されているので、自分で Arduino にモータードライバーをつけるよりも開発は楽になりそうです。 公式のチュートリアル が充実しているのも嬉しいですね。
正直、RECore の特徴を生かした使い道がまだ思いついていないけれど、色々と遊べそうなので、しばらくいじってみようと思っています。
SkypeでSIGMA fpをウェブカメラとして使いたい (Linux)
最近、リモートワークが流行したお陰で、ビデオ会議をする機会が増えました。 ビデオ会議をしていると、カメラの画質や画角に不満を感じる方も多いのではないでしょうか。 ノートパソコン内臓のウェブカメラの画質は筆舌に尽くしがたいものがあります。 ISOノイズたっぷりの映像に、ダイナミックレンジが低すぎて立体感が失われた日には、誰も貴方の顔を認識できないでしょう。 「人の顔のようなもの」がずらりと並んだ画面を見て、恐怖を感じた人もいると聞きます。 一説によると、ビデオ会議中に猫が現れるのは、飼い主をその恐怖から守るためだと言われています。
そんな闇鍋のようなビデオ会議を卒業するため、最高級のウェブカメラである SIGMA fp を Skype で使ってみます。 私の覚書なので、Linux のことしか考えていません。
Skype では SIGMA fp を使えない
SIGMA fp はパソコンと接続するときに「マスストレージ」と「ビデオクラス (UVC)」を選択できます。 UVC を選択すると、パスコンからはウェブカメラと同じカメラデバイスとして認識されるので、超絶高画質な映像をニャンニャンできるというわけです。 Zoom だと複雑な設定をしなくても、SIGMA fp を使うことができます。
しかし、Skype ではどうもうまくいきません。MacとLinuxで試してみた所、どちらでもウェブカメラとして使えませんでした。 今までは、別なソフトでカメラ画像を表示して、それをスクリーンキャプチャして配信して凌いできました。 この知性のかけらもない実現手段に、枕濡らした夜は数えきれません。
アイディア
OBS Studio のプラグインである obs-v4lsink を使います。 Linux ではカメラデバイスは v4l (Video4Linux) で扱っています。 ループバックカメラデバイスを作るカーネルモジュールを組み込むことで、仮想的にカメラとして認識されるデバイスを作ることができるので、そこに OBS の映像を流す段取りです。
セットアップ
v4l2loopback のインストール
仮想カメラデバイスを作る v4l2loopback はパッケージが既にあるので、インストールは簡単です。
sudo apt install v4l2loopback-dkms v4l2loopback-utils
インストール後、カーネルに組み込みます。
sudo modprobe v4l2loopback
組み込まれたか確認します。
$ lsmod | grep v4l v4l2loopback 36864 0 videobuf2_v4l2 28672 1 uvcvideo videobuf2_core 36864 2 uvcvideo,videobuf2_v4l2 v4l2_common 16384 1 videobuf2_v4l2 videodev 180224 5 uvcvideo,v4l2loopback,v4l2_common,videobuf2_core,videobuf2_v4l2
また、ビデオデバイスの情報を v4l2-ctl で確認してみます。
$ v4l2-ctl --list-devices
Dummy video device (0x0000) (platform:v4l2loopback-000):
/dev/video1
NEC HD WebCam (usb-0000:00:14.0-4):
/dev/video0
私の環境では /dev/video1 が仮想デバイスに割り当てられているようです。
obs-v4l2sink のインストール
OBS Studio のインストールは簡単なので省きます。公式サイト通りにインストールして下さい。
obs-v4l2sink も https://github.com/CatxFish/obs-v4l2sink に従ってやればいいのですが、一応手順を書いておきます。
sudo apt install qtbase5-dev git clone git@github.com:CatxFish/obs-v4l2sink.git git clone --recursive https://github.com/obsproject/obs-studio.git mkdir obs-v4l2sink/build cd obs-v4l2sink/build cmake -DLIBOBS_INCLUDE_DIR="../../obs-studio/libobs" -DCMAKE_INSTALL_PREFIX=/usr .. make -j4 sudo make install
OBS Stduio の設定
画面下の「ソース」に「映像キャプチャデバイス」を追加します。

新規作成をチェックし、「SIGMA fp」と入力します。

SIGMA fp を UVC モードでパソコンに接続しておきます。 次の画面で SIGMA fp をデバイスとして選び、OK を押します(他の設定は変えなくて良い)。

ソースが追加されたら、画面上部のメニューの「ファイル」から「設定」を選び、「映像」の出力解像度を「640x360」まで下げます。 他の解像度でも配信はできますが、大きい解像度ほど遅延が大きくなる可能性があります。

設定完了後、メニューの「ツール」から「V4L2 Video Output」をクリックします。

仮想ビデオデバイスを指定して、「Start」します。

これで、SIGMA fp の映像がリサイズされて仮想カメラデバイスに転送された状態になります。
Skype 側の設定
「Dummy Video Device」を選ぶと、あら不思議!SIGMA fp の映像が Skype で使えるようになります!

レンズポエムを自動生成するお話
この記事は Zenn に移動しました。
タイムラプス動画の作り方
タイムラプス動画を作る機会があったので、やり方をメモしておきます。 簡単だよ!
TL;DR
ls -t1 *.jpg | tac | nl | awk '{print "mv", $2, $1.".jpg"}' | sh ffmpeg -r 24 -i ./%d.jpg -vcodec libx264 -y -s 1920x1080 ./output.mp4
問題:ffmpegは1から始まる連番画像しか変換できない
1.jpg, 2.jpg, ... という連番画像ファイルを用意して、
ffmpeg -r 24 -i ./%d.jpg -vcodec libx264 -y -s 1920x1080 ./output.mp4
とやれば動画のできあがりです。
簡単ですが、ffmpegは1から始まる連番ファイル名じゃないと、動画が作れません。
大抵のデジカメのファイルって、DSC5621.jpg とか _MG_2912.jpg みたいにデジカメ側が割り当てた番号が振られてますよね。
番号が1が始まることは、殆ど無いので、どうやってスマートにファイル名を変換するかが命です。
連番ファイル名の変換
ぱっと思いつく方法だと、for でできる。でも、なんかかっこ悪い。ワンライナーが良い。
f=($(ls -t1 *.CR2)); for i in $(seq 1 ${#f[@]}); do mv "${f[$i]}" "$i.jpg" done
調べているうちに、行番号をつけるコマンド nl を使う方法を思いついた。
ls -t1 *.jpg | tac | nl | awk '{print "mv", $2, $1.".jpg"}' | sh
最後、シェルコマンドを生成して実行するのは反則っぽいけど、ワンライナーでいける!やっほい!
Raspberry Pi でストレージのベンチマーク
Raspberry Pi は標準で MicroSD カードをブート・ルートボリュームに使う。MicroSD ってどれくらいの速度性能があるのか、気になったので、簡単に計測してみたので、メモ。
測定環境・デバイス:
- Raspberry Pi 3 Model B (Element14)
- MicroSD: 三菱ケミカルメディア Verbatim microSDHCカード 16GB Class4
- SD card reader: Elecom MR-A39NBK
- HDD: SEAGATE ST3500320AS 500GB SATA300 7200rpm
MicroSD、カードリーダは家電量販店で一番安いやつを買っています。HDD は家にたまたまあったお古を使っています。
MicroSD から起動して、自身のルートボリュームを読み書き
Raspberry Pi ボードに組み込まれている MicroSD ポートを使っています。
$ dd if=/dev/zero of=/tmp/dd.tmp ibs=1M obs=1M count=1024 status=progress 1050673152 bytes (1.1 GB, 1002 MiB) copied, 107.031 s, 9.8 MB/s 1024+0 records in 1024+0 records out 1073741824 bytes (1.1 GB, 1.0 GiB) copied, 112.657 s, 9.5 MB/s
やっぱ、安いやつだと遅いのでしょうか。フラッシュメモリならもう少し出るかと思っていましたが...
同型の MicroSD を USB 接続
$ dd if=/dev/zero of=/mnt/sdcard/tmp/dd.tmp ibs=1M obs=1M count=1024 status=progress 1072693248 bytes (1.1 GB, 1023 MiB) copied, 138.028 s, 7.8 MB/s 1024+0 records in 1024+0 records out 1073741824 bytes (1.1 GB, 1.0 GiB) copied, 138.108 s, 7.8 MB/s
2 MB/s ほど、速度が落ちました。カードリーダ + USB のオーバーヘッドですかね。
USB 接続した HDD
$ dd if=/dev/zero of=/mnt/hdd/tmp/dd.tmp ibs=1M obs=1M count=1024 status=progress 1067450368 bytes (1.1 GB, 1018 MiB) copied, 30.021 s, 35.6 MB/s 1024+0 records in 1024+0 records out 1073741824 bytes (1.1 GB, 1.0 GiB) copied, 30.2309 s, 35.5 MB/s
HDD、速いな!MicroSD ポートの 3.5 倍超ですね。こんなに速いとは意外です。
USB 接続した HDD から起動して、自身のルートボリュームを読み書き
Pi 3 から使えるようになった USB ブートで HDD からブートして、自分自身のルートボリュームの読み書き速度を測ってみます。
$ dd if=/dev/zero of=/tmp/dd.tmp ibs=1M obs=1M count=1024 status=progress 1039138816 bytes (1.0 GB, 991 MiB) copied, 31.0132 s, 33.5 MB/s 1024+0 records in 1024+0 records out 1073741824 bytes (1.1 GB, 1.0 GiB) copied, 31.7067 s, 33.9 MB/s
ちょっと下がったような気もしますが、誤差の範囲でしょう。
案外、HDD が速くて意外です。