品名予測の技術紹介
OPENLOGI Advent Calendar 2021 の13日目の記事です。
今年から、OPENLOGI というベンチャーで、会社で1人目の機械学習エンジニアとして働いています。 弊社は物流プラットフォームサービスを開発しており、今年から機械学習やデータ分析、数理最適化を通して物流を効率化しよう!という取り組みを始めました。 その一環で品名予測を Keras で実装したのですが、諸事情で使われないことになってしまいました。 悲しいので、供養のために技術面の話をここで紹介したいと思います。
品名とは?
大抵の方は、荷物を送るときにクロネコヤマトや佐川急便、郵便局を利用したことがあると思います。 そのとき、荷物の送り状(伝票)にダンボール箱の中身に何が入っているか書いた経験があるのではないでしょうか? 例えば、どこかのブランドの服を送る時は「衣料品」、とらやの羊羹セットをおくるときは「羊羹」などと書くと思います。 書き方については、佐川急便のヘルプページがわかりやすいと思います。
品名は、配達員が荷物を届けるときには「割れやすいか」「上に物を乗せて大丈夫か」などを判断するために必要な情報です。 しかし、配送会社側でも明確な定義は作っておらず、「こんな感じで書いてね」という具体例程度の情報しかありません。 このため、商品によってはいい感じの品名を思いつくのが難しかったりします。
品名予測とは?
弊社では、お客様のお荷物をお預かりして、配送することが日常的に行われています。 商品を送る際に、お客様に入力してもらった品名をもとに「配達員にとってわかりやすい品名」を予測するタスクを「品名予測」と呼んでいます。 例えば、「Perfume Single Vol.1」みたいな品名が入力されると、「CD/DVD」のように訂正した品名を推定します。 このような商品名に近い文字列が品名として入力されることが多く、品名訂正を自動化したいという要望が社内にありました。
予測システムの入力は
- お客様に入力してもらった品名(ヒント品名)
- 商品名
- 商品の大きさと重量
であり、出力は
- 配達員にとってわかりやすい品名(出力品名)
です。
出力品名は人間が作った教師データが数万件あるので、これを使って教師あり学習をします。
技術の概要
今回は以下のような技術セットで実現しました。
Seq2seq を選んだ明確な理由はないです。 今時は Transformer を使うのが主流なので、次は Transformer ベースの深層NNの事前学習モデルを改造していく方針でやりたいですね。
ライブラリに関しても、PyTorch でモデルを組んで JAX で学習して、 学習済みモデルを TFLite にエクスポートして Tensorflow で予測を回すみたいなピタゴラスイッチをどこかで見かけたので、 試してみたいですね。
前処理
ヒント品名と商品名は自然言語なので、一般的な自然言語処理でよく使われる前処理をかけています。
- neologd 正規化
- 形態素解析
- ストップワード除去
- その他の正規化処理
商品サイズと重量に関してはビニングすることで、カテゴリカル素性に変換しています。
形態素解析
自然言語で書かれた文字列を単語のリストに分解する処理を形態素解析といいます。 英語などでは必要ありませんが、日本語のように分かち書きされていない言語では必要な処理です。 最近は形態素解析せずに文字単位で直接処理できるニューラルネットもありますが、今回は単語単位で処理することにしました。
形態素解析は昔から研究されているトピックで、既に簡単に使えるツールがあります。 ツールとしては MeCab が一番有名ですね。 条件付き確率場を使っていて、非常に高速で使いやすいインタフェースです。 色々な言語でバインディングライブラリがあるので、Python や C 以外で形態素解析する場合も有力な選択肢になります。 Mac なら brew でインストールできます。
brew install mecab mecab-ipadic mecab
最近寒いですがお元気でしょうか? と入力すると、こんな感じで解析結果を出してくれます。
最近 名詞,副詞可能,*,*,*,*,最近,サイキン,サイキン 寒い 形容詞,自立,*,*,形容詞・アウオ段,基本形,寒い,サムイ,サムイ です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス が 助詞,接続助詞,*,*,*,*,が,ガ,ガ お 接頭詞,名詞接続,*,*,*,*,お,オ,オ 元気 名詞,形容動詞語幹,*,*,*,*,元気,ゲンキ,ゲンキ でしょ 助動詞,*,*,*,特殊・デス,未然形,です,デショ,デショ う 助動詞,*,*,*,不変化型,基本形,う,ウ,ウ か 助詞,副助詞/並立助詞/終助詞,*,*,*,*,か,カ,カ ? 記号,一般,*,*,*,*,?,?,? EOS
他にもいろいろな形態素解析の実装がありますが、MeCab で事足りることが多いので、個人的には MeCab を使うことが多いです。
形態素解析をやる場合は辞書でかなり精度が変わります。
辞書に関してはデフォルトの ipadic よりも mecab-ipadic-neologd が優秀です。
この辞書を使ったときに この素晴らしき世界に祝福を が固有名詞として認識された時はさすがに驚きました。
たぶん、私よりも語彙力があります。うらやま
ストップワード除去
ストップワード除去は出現頻度が高すぎる単語をあらかじめ除去しておくことです。 日本語でよく見かけるのは「です」「ます」「は」などの助詞ですね。 こういった単語は、ほとんど予測の役に立たないので削除します。
その他の正規化処理
【】《》×「」『』〈〉〔〕=〜※・! などの無意味な記号を除去したり、細かく雑多な前処理を追加でかけています。
よく使われる s/[0-9]+/0/g という変換もかけています。
例えば、USB扇風機 2021年最新モデル を USB扇風機 0年最新モデル に書き換えるような前処理です。
数字の細かい値は予測に関係ないので、情報を捨てて、単語数を減らしています。
モデル
ニューラルネットの全体の構造は以下のようになっています。 基本的には Encoder+Decoder で構成される Seq2seq モデルを拡張したような構造になっています。
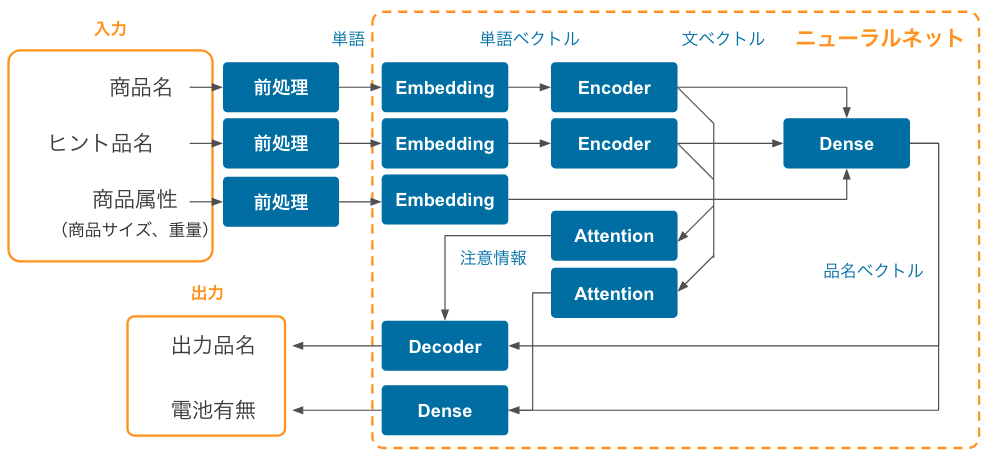
※ 航空便などでは電池の有無で配送不可になることがあるので、出力品名とはわけて予測しています。
Embedding
人が読み書きする言語には必ず、類義語や表記揺れがあります。 例えば、「MacBook」と「レッツノート」は似たような意味の単語ですが、文字列としては全然違います。 文字列だけで比較してしまうと、両者から「ノートパソコン」という同じ品名を導くことが難しいので、 類義語や表記揺れを吸収した「単語の意味っぽい」情報を取り出す必要があります。 この処理を担当するのが Embedding レイヤーです。
専門的には、Embedding レイヤーは単語の Bag-of-words 表現を分散表現という密ベクトルに次元圧縮する処理を行います。 この密ベクトルのコサイン類似度は直感的な単語の類似度に近くなることが知られています。 気になる方は Word2vec で調べてみてください。深い沼が貴方を待っています。
Seq2seq Encoder
Seq2seq の Encoder は入力単語列(正確には入力単語の分散表現の列)を受け取って、context というベクトルにまとめる処理を担当します。 例えば、以下に「岩下の新生姜ファミリーパック」という商品名を入力した場合のネットワーク構造を図示しています。
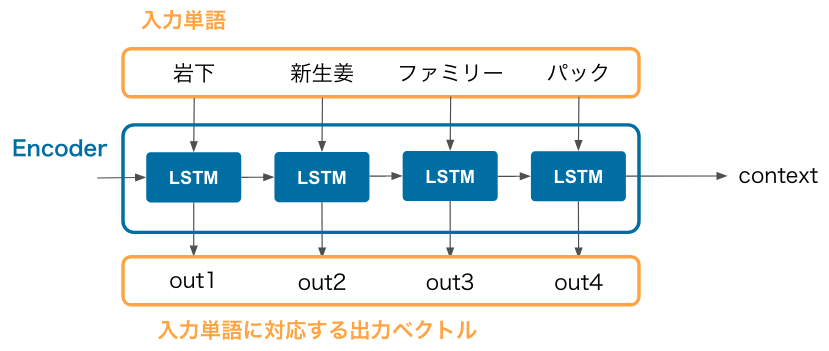
Recurrent Neural Network の一種である LSTM を連結した構造になっており、 入力単語の個数に関係なく、固定長の context ベクトルが得られる点が Seq2seq の特徴です。 context は商品名全体の特徴を持ったベクトルなので、このベクトルに対して色々と処理ができます。
入力単語に対応する出力ベクトルは Attention レイヤーに渡されます。
Seq2seq Decoder
Seq2seq の Decoder は Encoder の成果物である context を受け取って、出力品名の単語を1つずつ予測します。 例えば、先程の「岩下の新生姜ファミリーパック」に対して「生姜酢漬け」という品名を予測する場合は以下のようになります。
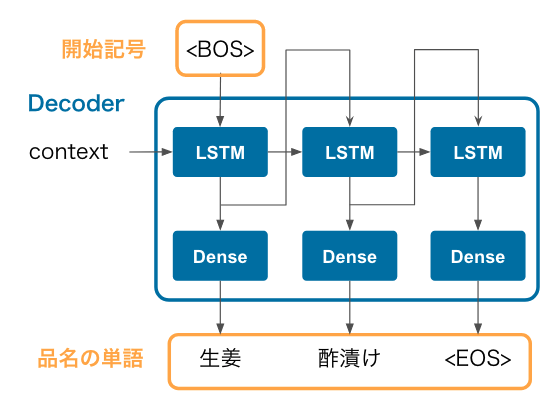
- まず、LSTM の入力に
<BOS>(文字列の開始を意味する特殊記号)を入力すると、生姜という単語が出力されます。 - 前のステップで得られた
生姜の出力ベクトルを次の LSTM の入力に入れると酢漬けという単語が出力されます。 - さらにこの
酢漬けの出力ベクトルを次の LSTM の入力に入れると<EOS>という文字列の終端を意味する特殊記号が出力されます。この記号が得られた時点で予測を止めます。
このように、1つ前の単語を LSTM に入力して、次の単語を予測する、という処理を繰り返して品名全体を予測します。
精度
Decoder で出力品名を求めるときに、単語列の同時確率を計算しておきます。 基本的には同時確率が高いほど、出力品名の信頼性が高いと考えられます。 適当にしきい値を決めて、この同時確率がしきい値を超えた品名だけ予測品名を採用し、 しきい値未満の品名は人間が確認するような Human-in-the-loop の運用を想定してみます。 興味があるのは、
- 自動化率:予測器に担当させられる(=しきい値を超える)品名の割合
- 精度:予測器に担当させた品名のうち、正解する品名の割合
の2つです。
今回実装したモデルでは、自動化率 36 %、精度 99.5 % で当てることができました。 半分以上の商品では、まだ十分な精度を出せませんでしたが、社内では「実戦投入しても良さそう」と思ってもらえるだけの精度を出すことができました。
プロジェクトが中止になったのは精度とは関係ない事情なので、初期実装としてはギリギリ使える数字になったと思います。
反省点
Seq2seq じゃなくて Transformer ベースの既存の DNN の事前学習モデルをベースに組み立てれば良かったな、と思っています。 多分その方が、少ない労力でもっと高精度を叩き出せたのではないかと考えています。